Data Science Life cycle
Overview
In this tutorial, let’s understand the life cycle of data science. Data science is a field that involves extracting insights and knowledge from data using various techniques and methodologies. It combines elements from computer science, mathematics, statistics, and domain-specific knowledge to analyze complex datasets and make informed business decisions. Statistical Analysis, Machine Learning, Data Mining, and Visualization are key techniques.
Data Science Life-cycle
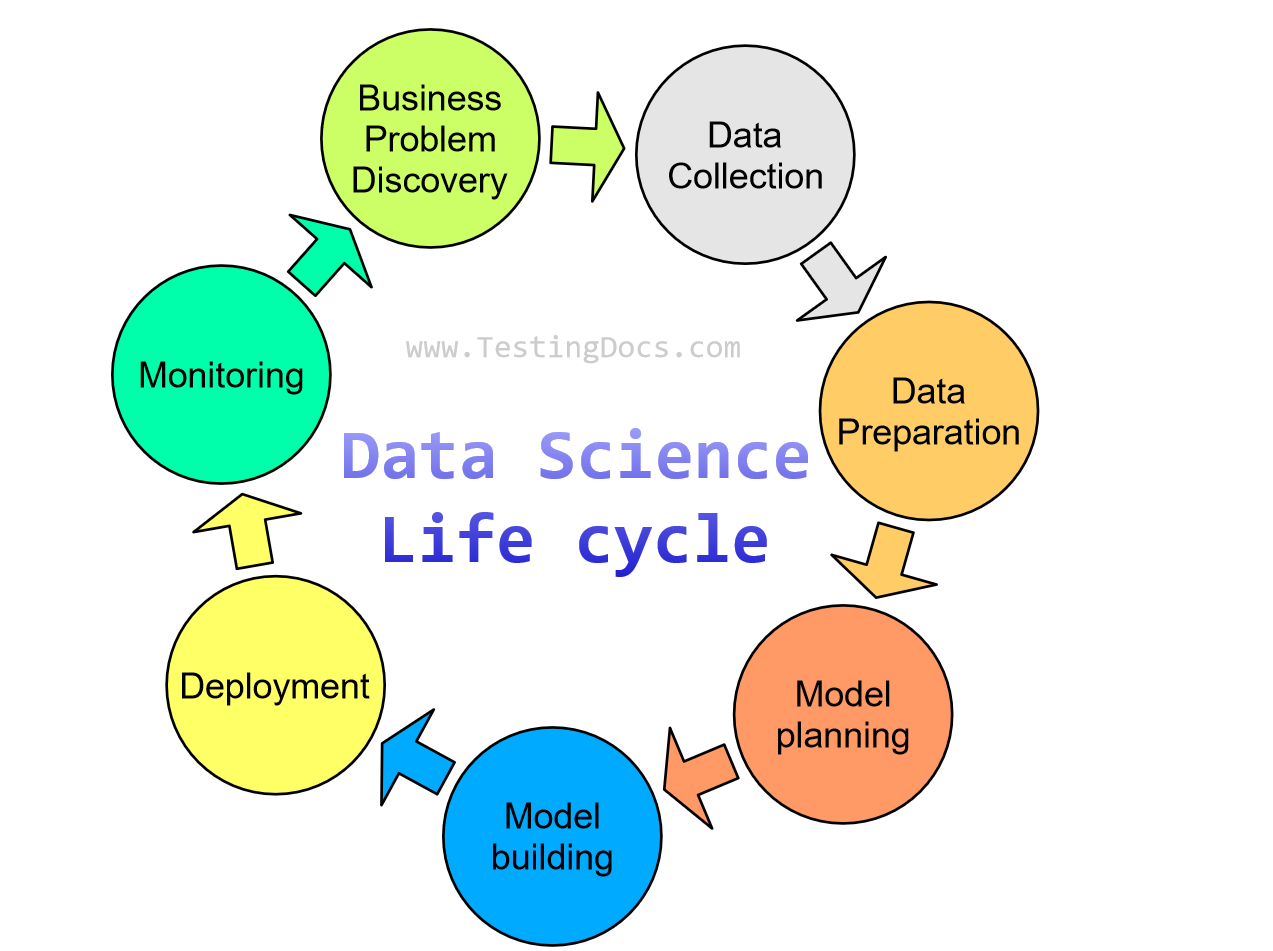
The Data Science cycle is an iterative process that aims to produce insights and make predictions to achieve business goals. Various steps are involved in the Data Science life cycle. The stages involved are as follows:
- Business Understanding
- Data Collection
- Data Preparation
- Model Planning
- Model building
- Deployment
- Monitoring
Business Understanding
This phase involves defining the problem to be solved and understanding the objectives.
Data Collection
The data collection step involves acquiring data from all the identified internal and external sources, which helps to answer the business question. The data can be from different sources:
- Files
- Databases
- Social media posts.
- Webserver Logs
- Data from APIs.
Data Preparation
Data can have many inconsistencies, such as missing values, black columns, and incorrect data format, which need to be cleaned.
This step involves data cleaning and ensures that the data is accurate, complete, and consistent by handling missing values, removing duplicates, and transforming data into a suitable format for analysis.
Model Planning
Select and apply various modeling techniques to the prepared data.
In this stage, appropriate models and techniques are applied to determine the relation between input variables and the prepared data. A model is planned using different statistical formulas and visualization tools.
Some tools are:
- R programming language
- SAS
- SQL Server Analysis
Model Building
In this step, the actual model building is done. The data scientist assesses the model to ensure it meets the business objectives. Techniques like association, classification, and clustering are applied to the training data set. Once done, the model is tested with the testing dataset.
Deployment
In this stage, you deliver the final baseline model with reports, code, and technical documents. After thorough testing, the model is deployed into a real-time production environment for practical use.
Monitoring
In this stage, the performance of the deployed model is continuously monitored and updated as new data becomes available, and the overall data infrastructure is maintained. The results are communicated to all stakeholders. Based on the inputs from the model, this helps you decide whether the project’s results are a success or failure
