Differences Between LangChain and RAG
Differences Between LangChain and RAG
Large Language Models (LLMs) are great at writing and reasoning, but they don’t automatically know your company docs, product catalogs, or today’s news. Two popular ways to build smarter AI apps are LangChain and RAG (Retrieval Augmented Generation). Think of LangChain as a developer toolkit for composing LLM workflows, and RAG as a design pattern for letting an LLM read from your own knowledge before it answers.
What is LangChain?
LangChain is an open-source framework that helps developers build LLM-powered applications by “chaining” components together. These components can include prompts, models, retrieval steps, tools (like web search or databases), and control logic such as branching or loops. LangChain provides ready-made abstractions (e.g., LLMs, ChatModels, Prompts, Document Loaders, Vector Stores, Retrievers, and Agents) so you can quickly assemble complex pipelines such as question-answering, document chat, or multi-tool agents.
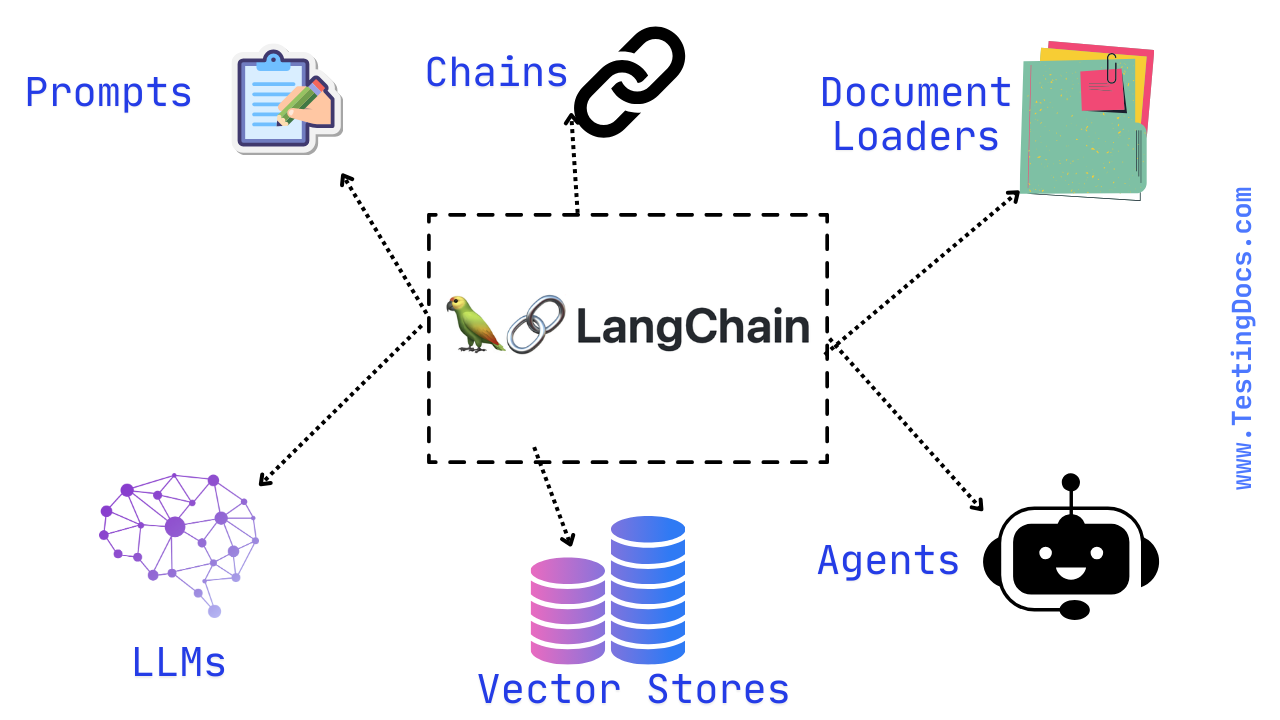
In short, LangChain is a framework that speeds up building and orchestrating LLM applications, regardless of whether you use RAG, tool use, or other patterns.
What is RAG (Retrieval Augmented Generation)?
Retrieval Augmented Generation (RAG) is an architecture pattern for improving an LLM’s answers by supplying it with relevant external context at query time. The common flow is:
- Split and index your documents (often into a vector database).
- At question time, retrieve the most relevant chunks.
- Give those chunks to the LLM in the prompt so it can ground its response.
RAG reduces hallucinations and keeps answers up-to-date because the model cites or uses retrieved content rather than relying solely on its internal training data.
LangChain vs RAG
Some of the differences between LangChain and RAG are as follows:
| LangChain | RAG (Retrieval Augmented Generation) | |
|---|---|---|
| What it is | Framework/library to build LLM apps | Design pattern/architecture for grounding LLMs with retrieved context |
| Primary focus | Orchestration of prompts, models, tools, memory, agents | Fetching relevant documents and injecting them into the prompt |
| Scope | End-to-end pipelines (RAG, agents, tools, workflows) | Specific flow: retrieve → augment prompt → generate |
| Key components | Chains, Agents, Tools, Retrievers, Vector Stores, Memory | Indexing/embedding, Retriever, Context construction, Generation |
| How they relate | Can implement RAG as one of many patterns | Can be implemented using LangChain (or any framework, or from scratch) |
| When to choose | When you want rapid development, modularity, and integrations | When you need accurate, up-to-date answers grounded in your data |
| Complexity | Provides many features; complexity depends on your pipeline | Conceptually simple; quality depends on retrieval and chunking |
| Typical outputs | Apps with multi-step logic, tool use, and memory | Answers that cite or rely on retrieved context |
| Vendor neutrality | Abstracts many LLMs, vector DBs, and tools behind one API | Independent concept; works with any LLM or database |
Nutshell
You don’t pick either LangChain or RAG in most real projects. Instead, you often build a RAG pipeline using LangChain (or another framework). RAG provides the grounding strategy; LangChain provides the building blocks and integrations to implement that strategy efficiently.