AI Distillation Concept
AI Distillation Concept
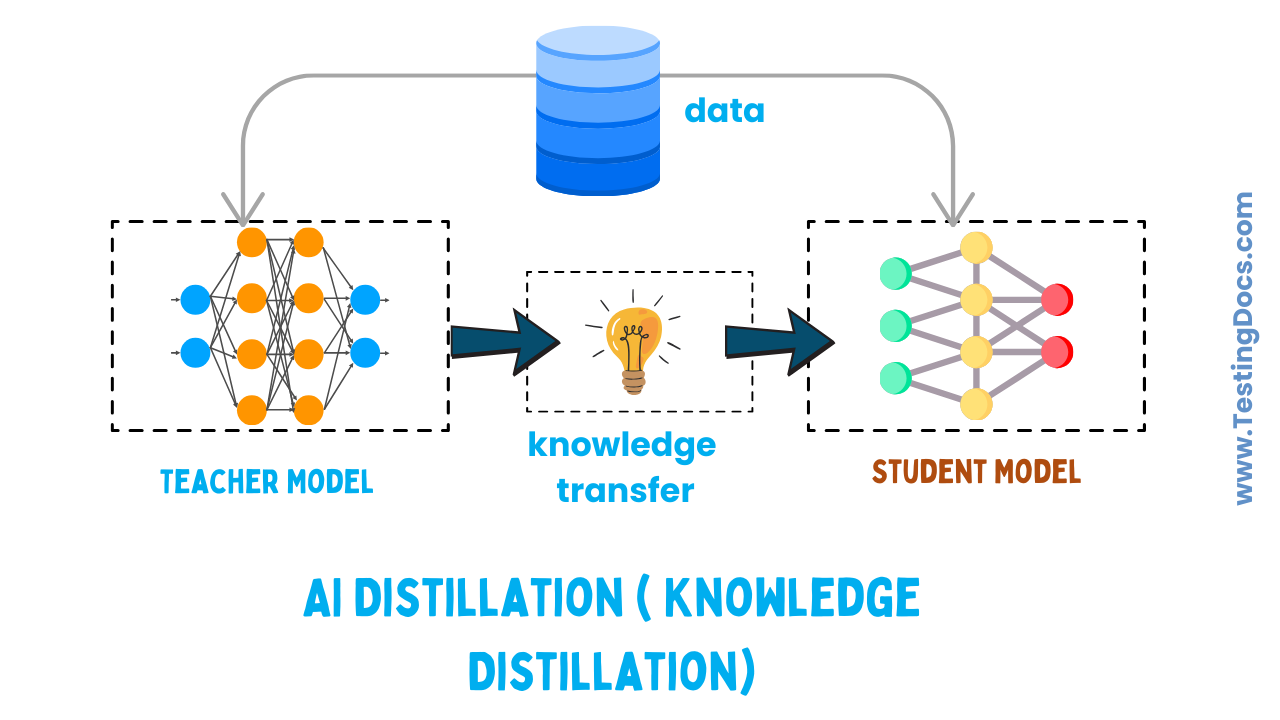
Large AI models (teacher models) perform exceptionally well but are slow, expensive, and hard to run on small devices. AI Distillation (Knowledge Distillation) is the process of transferring the “knowledge” of a large model into a smaller, faster model (student model). This allows us to keep most of the accuracy while gaining speed and efficiency.
Introduction to AI Distillation
Knowledge Distillation means passing the learning of a “teacher” model into a “student” model.
The teacher is usually very large and highly accurate, while the student is lightweight and designed for mobile, edge devices, or low-latency tasks.
The core idea: instead of training only on hard labels (0/1), the student learns from the teacher’s “soft targets” (probability distribution across classes), which carry richer information.
- Soft Targets: Instead of binary labels, the teacher provides probabilities (e.g., cat = 0.7, dog = 0.2), which give subtle learning signals.
- Generalization: The teacher’s output carries useful hints that help the student generalize better.
- Regularization: Soft targets reduce overfitting, making the student more stable.
Distillation Approach & Process
- Train a Teacher: Start with a large, accurate teacher model (e.g., a big transformer or CNN).
- Design a Student: Build a smaller model with fewer layers or parameters.
- Generate Soft Labels: Run the teacher on training data and capture probability distributions. Temperature scaling is often used to soften the distribution.
- Define the Loss: Train the student using:
- Task loss (e.g., cross-entropy on true labels).
- Distillation loss (e.g., KL divergence to match teacher’s outputs).
Total Loss = α × task loss + (1−α) × distillation loss.
- Train & Validate: Optimize the student, balancing accuracy, latency, and memory usage.
- Deploy: Use the student in production (mobile, edge, or server environments).
Example (Image Classification)
Scenario: You’re building an app to classify animal images — dog, cat, bird, rabbit.
- Teacher: Large CNN with 100M parameters, 92% accuracy, 120ms latency.
- Student: Small CNN with 8M parameters, target: ≥90% accuracy, <40ms latency.
Procedure:
- Run the teacher on the dataset and collect soft outputs like [dog: 0.70, cat: 0.20, bird: 0.07, rabbit: 0.03].
- Train the student with:
- Cross-entropy loss on the true label (dog).
- KL divergence loss to mimic the teacher distribution (with temperature T=2 or 4).
- After tuning α and T, the student reaches ~91% accuracy with just 35ms latency.
- Deploy the student for faster, battery-efficient app performance.
Teacher vs Student
| Teacher Model | Student Model | |
|---|---|---|
| Size | Large (millions/billions of parameters) | Small (fewer parameters) |
| Speed/Latency | Slow | Fast |
| Accuracy | Very high | Close to teacher |
| Deployment | Server/High-end GPU | Mobile/Edge devices |
Variants of Distillation
Some of the variants are as follows:
- Logit Distillation: Matching teacher’s probability outputs.
- Feature Distillation: Student mimics intermediate features of the teacher.
- Hint-based Distillation: Using feature maps or layer outputs as hints.
- Sequence Distillation (NLP): Matching token distributions in language models.
Benefits of AI Distillation
Some of the benefits of AI distillation are as follows:
- Lower Latency: Faster responses in apps like chatbots, vision, and speech systems.
- Reduced Cost: Less computation, fewer GPU/CPU cycles, lower electricity bills.
- Edge Deployment: Easier to run on mobile or IoT devices.
- Better Generalization: Soft labels improve performance on unseen data.
- Model Compression: Can be combined with pruning and quantization for further optimization.
Common Tips & Pitfalls
- Temperature (T) Tuning: Too low = sharp distribution; too high = blurry signals. Tune carefully.
- Loss Weight (α): Balance task loss vs distillation loss properly.
- Data Coverage: Train the student on diverse data for robustness.
- Architecture Fit: Student should be capable enough to capture the teacher’s signals.
Use cases
- Mobile vision apps (object detection, OCR).
- Real-time chat and voice assistants.
- Edge IoT devices in healthcare, retail, or industry.
- Server-side deployments to cut inference costs.
AI Distillation transfers knowledge from a large teacher model into a smaller student model.
By training with soft targets and task loss, the student achieves near-teacher accuracy while being faster, cheaper, and easier to deploy.