Supervised Learning
Supervised Learning
Supervised Learning is a type of Machine Learning where a model learns from labeled data.In this method the model is trained with labeled datasets. This means that the model is provided with input-output pairs, where the input data has corresponding correct outputs.
How Supervised Learning Works?
Supervised Learning involves training a model using a dataset that contains both input features and the corresponding correct answers (labels). In this method the input data is labeled. We train the model with the input and corresponding output.
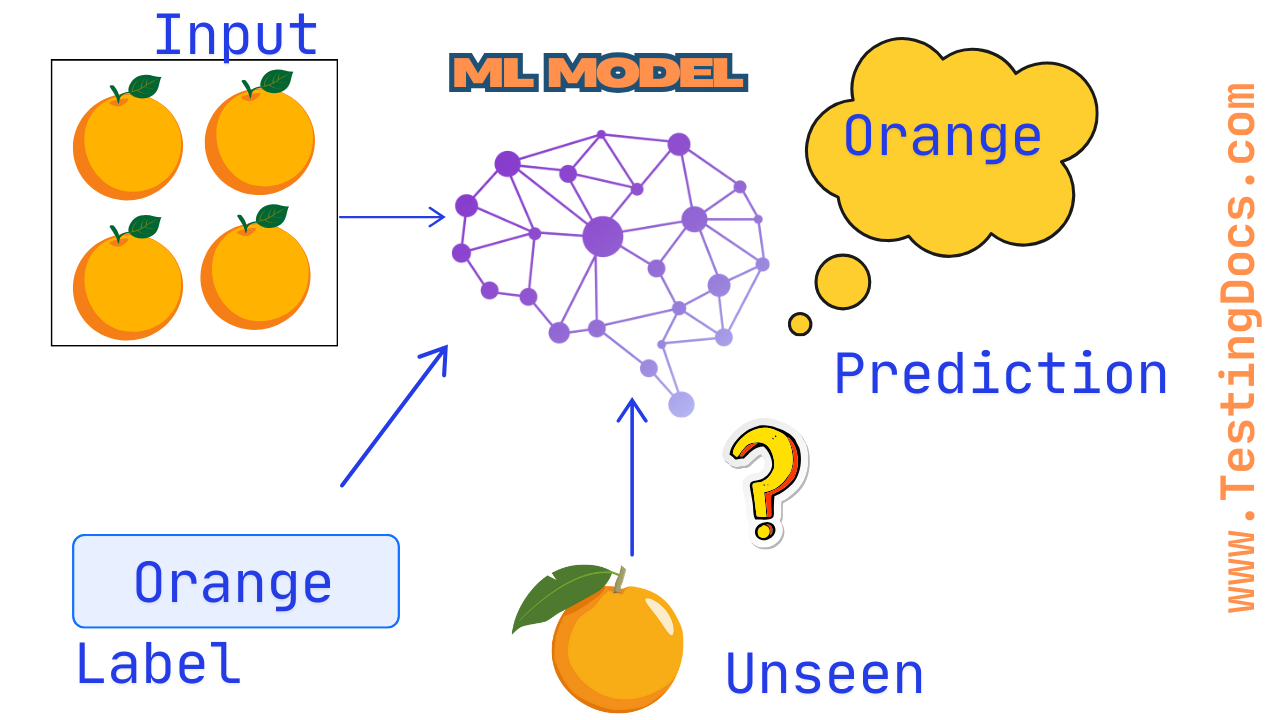
The goal of the model is to learn the relationship between inputs and outputs so that it can make accurate predictions on new, unseen data. The model is adjusted over time to minimize the error in its predictions. Once trained, it can be used to classify new data or make numerical predictions.
Types of Supervised Learning
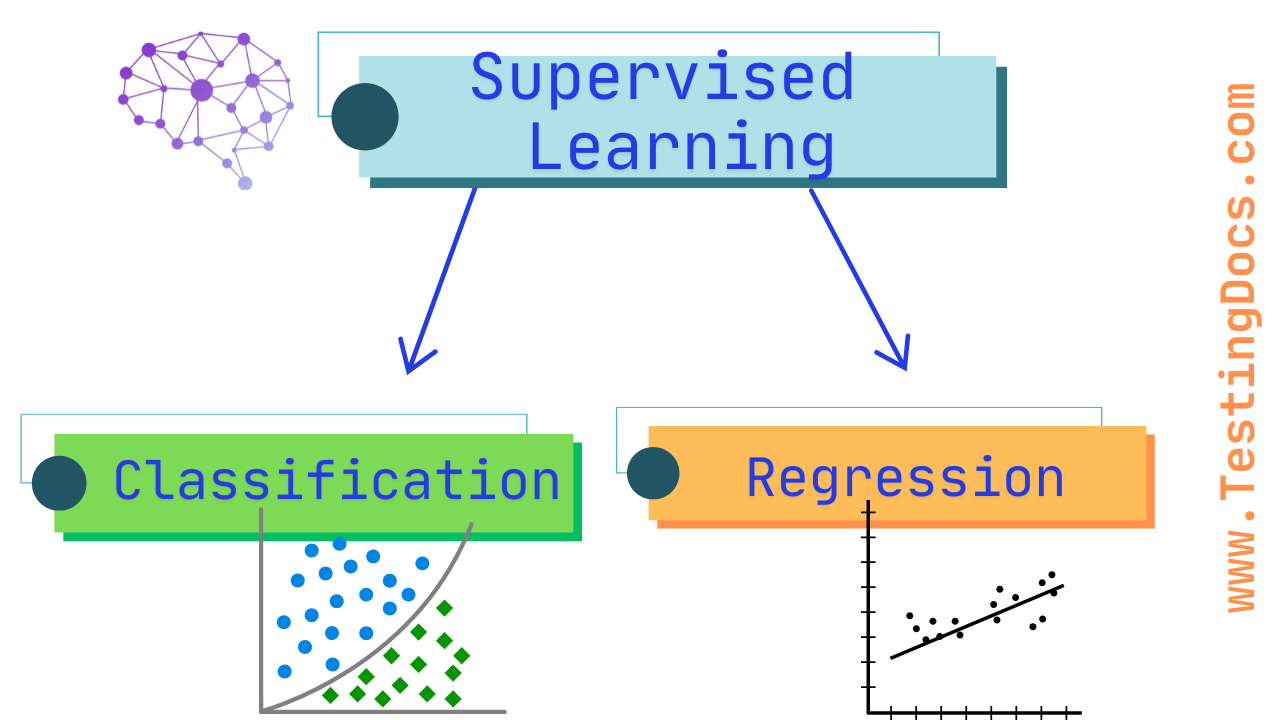
Different types of Supervised Learning are as follows:
Classification
Classification is used when the output is categorical, meaning it belongs to a specific group or class. Examples include spam detection (spam or not spam) and handwriting recognition.
Regression
Regression is used when the output is continuous, meaning it is a number rather than a category. Examples include predicting house prices and stock market trends.
Advantages of Supervised Learning
- Produces highly accurate results when given sufficient labeled data.
- Can be applied to a wide range of real-world problems, such as speech recognition and fraud detection.
- Easy to understand and interpret since the training data is labeled.
Disadvantages of Supervised Learning
- Requires a large amount of labeled data, which can be time-consuming and expensive to obtain.
- May not perform well if the training data is biased or not representative of real-world scenarios.
- Limited ability to adapt to new data that differs significantly from the training dataset.
Example of Supervised Learning
Imagine you are building a model to predict whether an email is spam or not. You collect a dataset containing thousands of emails labeled as “spam” or “not spam.” The model is trained on this data by identifying patterns such as certain keywords, email sender addresses, and formatting styles. Once trained, the model can analyze new emails and classify them as spam or not spam with high accuracy.
