Frequency Penalty
Frequency Penalty
The frequency penalty setting suppresses or allows the model to repeat while generating the response. This tutorial will teach us how to set this setting using OpenAI Playground or API requests.
Frequency Penalty indicates how the model penalizes new tokens based on their existing frequency in the text. A high value of this setting will decrease the likelihood of the model repeating the same line verbatim by penalizing new tokens that have already been used frequently.
Adjust the Setting
We can adjust the setting using the OpenAI Playground or in the API call.
Playground
Sign in to the Playground.
Click on the Playground menu in the left navigation bar.
Choose the flavor, like Chat or Assistant, that you want to test.
Pick the model.
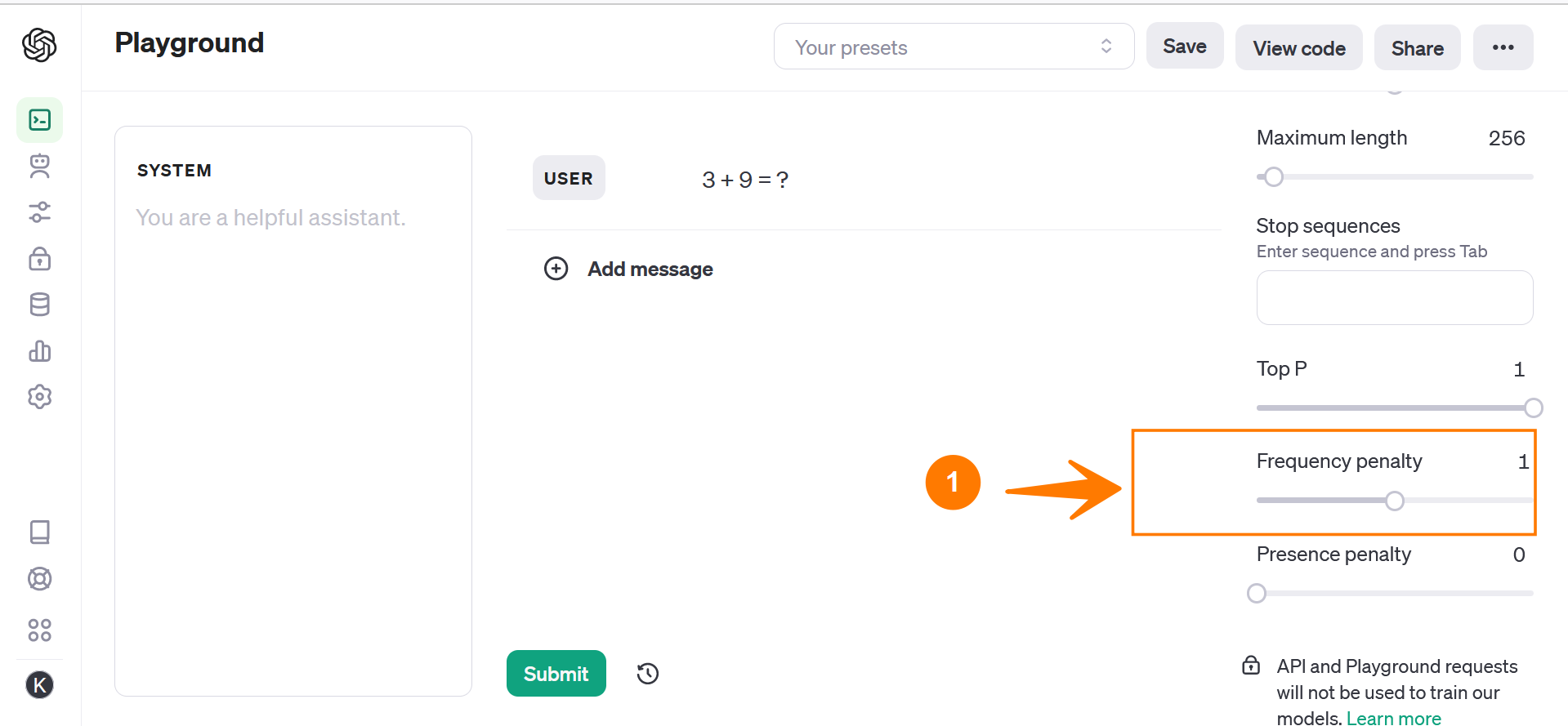
Slide the Frequency penalty slider to set a value. The range of the value is from o to 2.
API Request
To set the value in the API request:
frequency_penalty=<value>
For example, to set the setting at 0.5, we can use the following:
frequency_penalty=0.5
Example
response = client.chat.completions.create(
model=”gpt-4-turbo-preview”,
messages=[
{
“role”: “user”,
“content”: user_prompt_goes_here
}
],
temperature=1,
max_tokens=256,
top_p=1,
frequency_penalty=0.5,
presence_penalty=0,
)


