OpenAI Tokenizer Tool
OpenAI Tokenizer Tool
In this tutorial, let’s learn about the OpenAI Tokenizer Tool. Large Language Models( LLMs) process text using tokens. Tokens are sequences of characters that the models learn to predict the next in a sequence. A token is a discrete unit of meaning in NLP(Natural Language Processing). Each token is represented as a unique integer, and the set of all possible tokens is called the vocabulary.
Out-of-vocabulary (OOV)
OOV words are those not explicitly present in the tokenizer’s vocabulary. Subword tokenization helps mitigate the impact of OOV words by decomposing them into subwords in the vocabulary.
| LLM Tokens | English text |
| 1 token | ~= 4 characters in the English language |
| 1 token | ~= ¾ word |
| 100 tokens | ~= 75 words |
One token is roughly equivalent to 4 characters or 0.75 words in English
language text.
OpenAI Tokenizer Tool
The OpenAI Tokenizer tool helps understand how language models process text.
We can access the tool at:
https://platform.openai.com/tokenizer
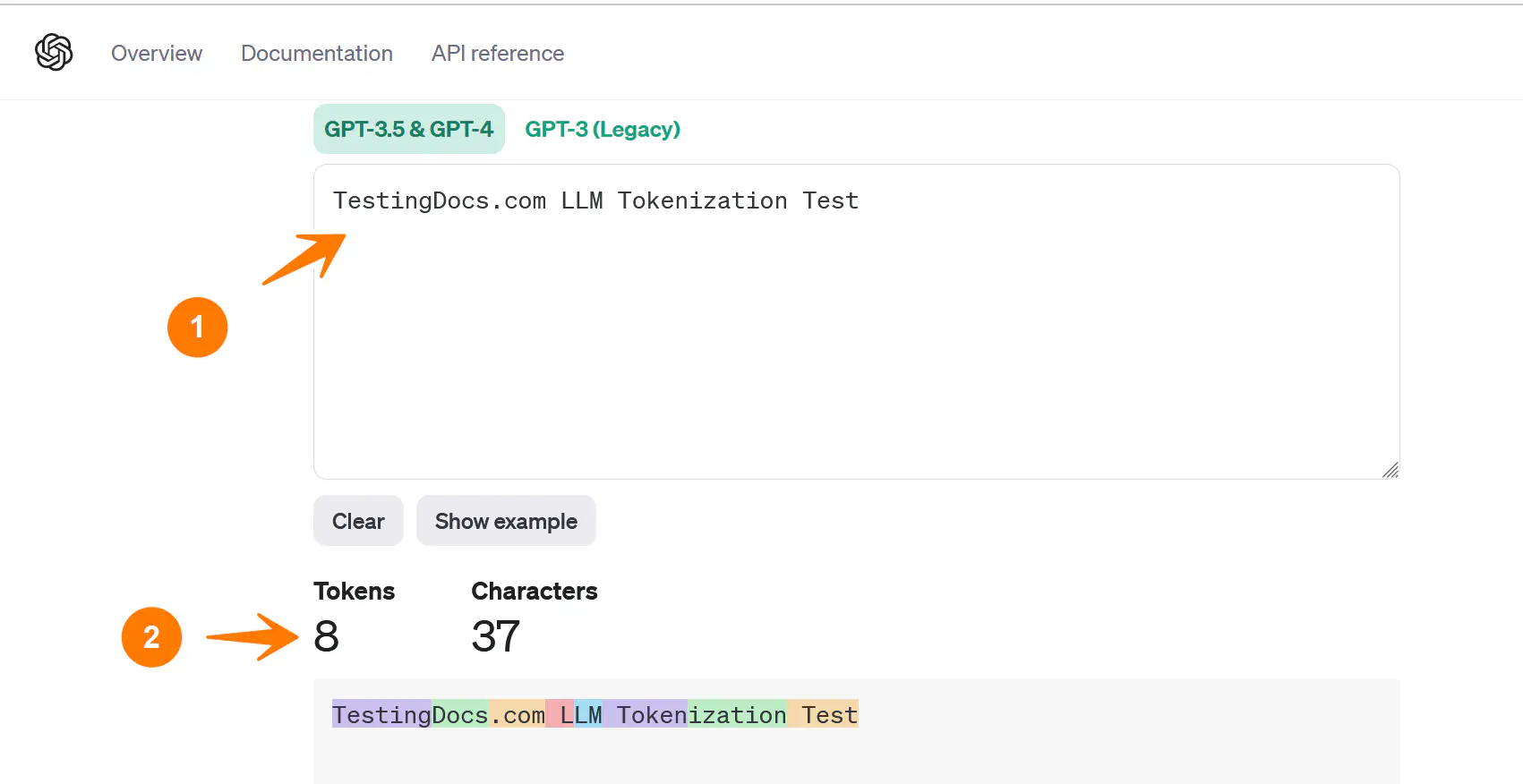
Note that the tokenization process varies between models. Newer models like GPT-4 use a different tokenizer than previous models and will produce different tokens for the same text.
Toggle to the GPT-3( Legacy ) model and check the tokenization.
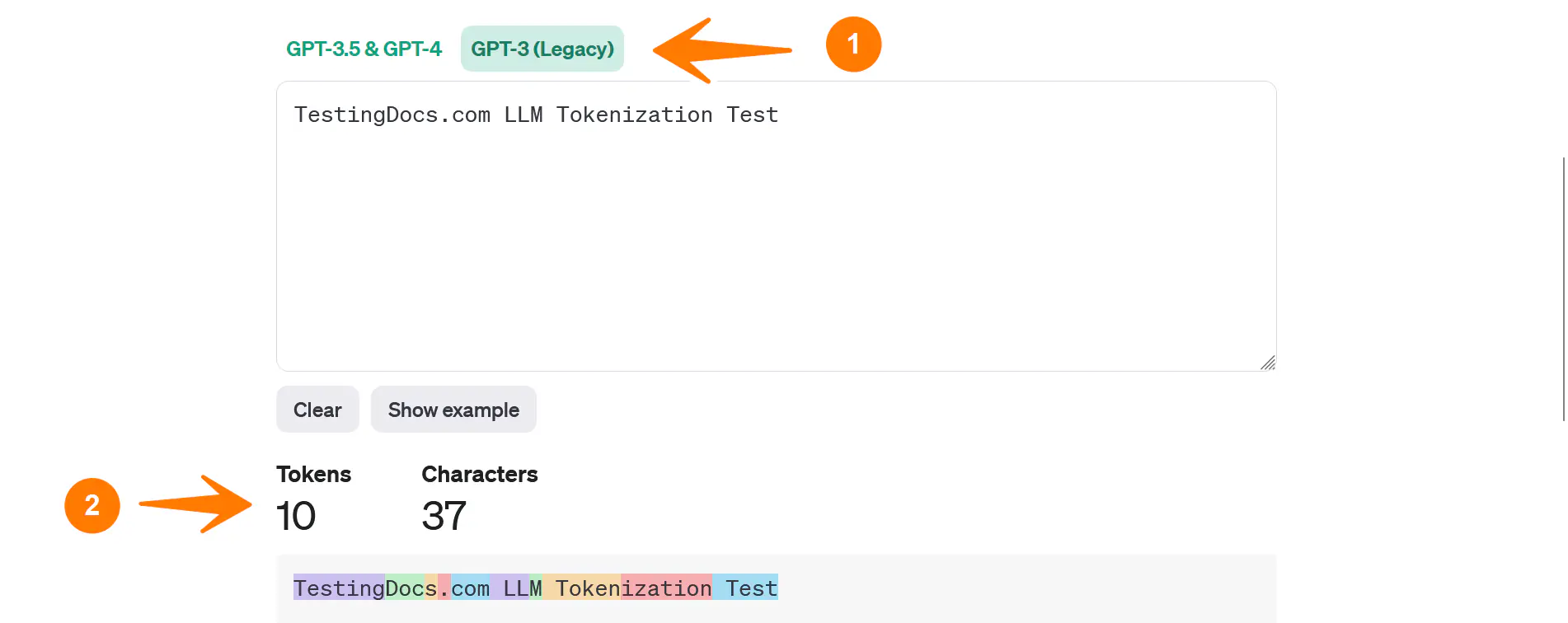
The tokenizer tool can show you how a piece of text might be tokenized and the total count of tokens in that piece of text. This is particularly useful for developers working with language models to understand better how the model interprets and processes their input text.
tiktoken Package
In Python language, we can split a string into tokens with OpenAI’s tokenizer Python package called tiktoken
To import the package:
import tiktoken
More information at: https://github.com/openai/tiktoken


